NVIDIA Vera Rubin Enters Full Production

NVIDIA has announced full production of its next-generation Vera Rubin AI platform at GTC 2026. Equipped with 288GB of HBM4 and delivering 50 petaflops of FP4 inference per GPU, the platform directly targets agentic AI workloads.
"One prompt can launch a thousand-step journey," declared NVIDIA CEO Jensen Huang at the GTC 2026 keynote. Announcing that the company's next-generation AI platform, Vera Rubin, has entered full production, Huang made clear that the architecture targets a new class of workload: agentic AI. Described by Huang as the most ambitious project in NVIDIA's history, the platform was developed by 40,000 engineers and is scheduled to begin shipping this fall.
Skipping an Entire Hardware Generation

The core innovation of the Vera Rubin architecture lies in the unprecedented scale of a single GPU. Each Rubin GPU is equipped with 288GB of HBM4 memory, delivering 22 TB/s of bandwidth alongside 50 petaflops of FP4 inference and 35 petaflops of FP4 training performance. Manufactured using TSMC's 3nm process in a dual-die configuration, the processor integrates 336 billion transistors—a 1.6-fold increase over the 208 billion transistors of the Blackwell generation.
This generational leap is clearly visible when comparing the platform to its predecessors. From the Hopper architecture (H100 and H200) through Blackwell (B200) to Rubin, key performance metrics—including memory capacity, bandwidth, and computational throughput—have increased by multiples at every transition.
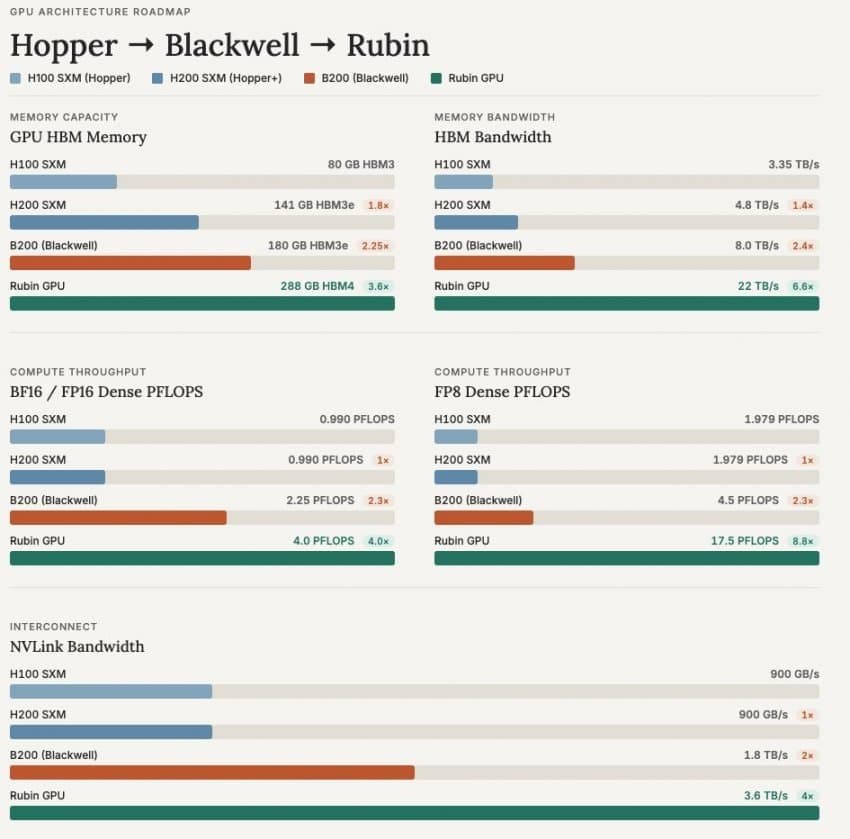
Specifically, memory bandwidth increased 6.6-fold from 3.35 TB/s on the H100 to 22 TB/s on the Rubin GPU, while FP8 compute capabilities grew by a factor of 8.8. In an era marked by the exponential growth of inference tokens, memory capacity and bandwidth serve as the ultimate bottlenecks for throughput. This explains why NVIDIA prioritized memory subsystem enhancements just as heavily as raw computational power — and why the Rubin GPU is being called a memory monster.
Why the Architecture Targets Agentic AI
The necessity of this massive computational capacity becomes clear when analyzing the changing nature of AI workloads. While traditional models generate a single, direct response to a prompt, agentic AI operates on an entirely different scale.
"Agentic AI is a new kind of workload. One prompt can launch a thousand-step journey of reasoning, retrieval, tool use and response generation." — Jensen Huang, GTC 2026
Chained processes—wherein an autonomous agent reasons independently, calls external APIs, and spawns secondary sub-agents—require thousands of times more compute cycles per query than standard search. This is the precise workload Vera Rubin was engineered to address. By linking GPUs and Vera CPUs via NVLink 6, the rack-scale Vera Rubin NVL144 system delivers a 10-fold increase in agent throughput compared to the previous Grace Blackwell architecture, alongside a 10-fold improvement in inference performance per watt and one-tenth the cost per token.
Under this architecture, the Vera CPU—featuring 88 custom Arm cores—efficiently offloads secondary operations like information retrieval and tool execution, allowing the GPU to remain fully dedicated to core inference. This hardware optimization aligns seamlessly with NVIDIA's broader software push for agentic AI, including the recently introduced NemoClaw platform.
Scaling Vera Rubin Across a Supply Chain Twice Blackwell's Size

Beyond raw performance metrics, NVIDIA emphasized the sheer industrial scale of the AI factory rollout. According to the NVIDIA newsroom, the supply chain supporting Vera Rubin has doubled in size compared to the Blackwell generation. This massive effort coordinates 150 partner companies in Taiwan alone, alongside more than 350 manufacturing facilities across 30 countries. Rather than a single processor, NVIDIA has simultaneously initiated production for seven distinct silicon components, including GPUs, CPUs, NVLink switches, and specialized networking chips. Together, these components form the building blocks of a single AI factory.
This unprecedented production volume is designed to stand up a new AI factory in data centers worldwide. Cloud service providers such as CoreWeave have signed on as early adoption partners, while the inference-optimized Vera Rubin CPX rack system is scheduled to debut before the end of the year.
Ultimately, the true significance of the Vera Rubin platform lies beyond raw compute speeds. As the tech industry transitions to an agentic AI model where a single query triggers thousands of sequential steps, the competitive landscape will be decided by who installs the infrastructure capable of absorbing this massive computational surge. By shifting its focus from discrete hardware components to turnkey AI factory infrastructure, NVIDIA is moving to establish the definitive infrastructure standard for an era where autonomous agents orchestrate other agents.



- NVIDIA Newsroom - NVIDIA Vera Rubin Ramps Into Full Production to Power Agentic AI Factories Worldwide
- NVIDIA Newsroom - NVIDIA Vera Rubin Opens Agentic AI Frontier
- Tom's Hardware - Nvidia's Vera Rubin platform in depth — Inside Nvidia's most complex AI and HPC platform to date
- SiliconANGLE - Nvidia ramps up production of Vera Rubin, the foundation of the next generation of AI factories
- CryptoBriefing - Nvidia CEO Jensen Huang unveils Vera Rubin production timeline at GTC Taipei 2026